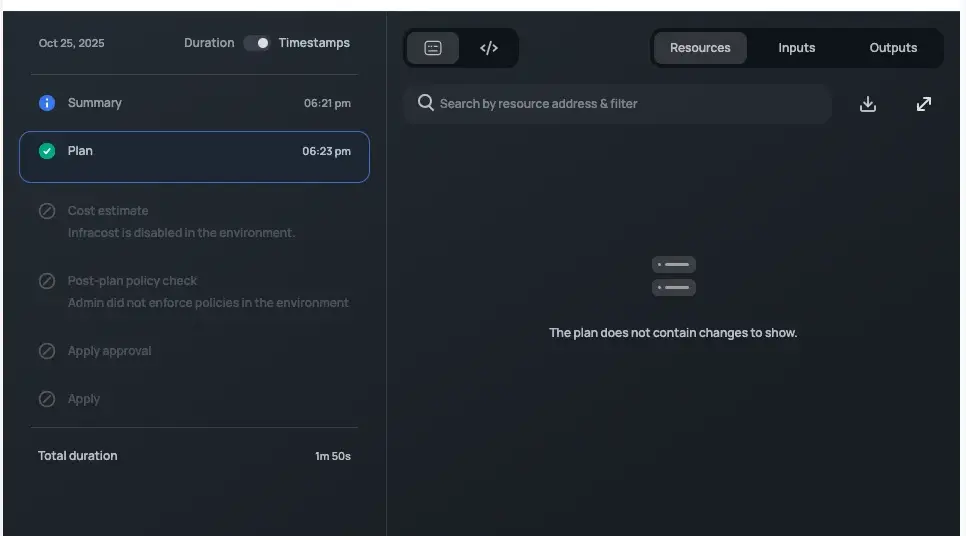
Finding a Way Around origin_shield Drift
Every Terraform plan flag a change in our CloudFront distribution (even when nothing is actually changing).
The issue was origin_shield. When it is disabled, AWS drops it from the response. Terraform sees it missing and adds it back with enabled = false every run.
So every run you would see CloudFront being changed. Big deal because it’s the CDN, misconfiguration could bring down a site. What ends up happening is we always had to inspect the change.
The obvious fix was to make the block dynamic so it only appears when origin shield is actually enabled.
dynamic "origin_shield" {
for_each = var.enable_cloudfront_origin_shield ? [1] : []
content {
enabled = var.enable_cloudfront_origin_shield
origin_shield_region = data.aws_region.current.name
}
}
Drift was gone, plans were clean. But then I found the other side of the problem.
If origin shield was enabled, then later disabled, Terraform would plan to remove the block. The plan looked right. Apply ran. Nothing happened. Origin shield stayed on in the AWS Console because the provider simply removed enabled = true but AWS needed an explicit enabled = false and we are back to the original problem.
We filed a bug report in April 2022. Three years passed, it’s still open.
I can’t fix the provider, but I really really wanted a clean plan/apply in our infrastructure.
I figured, I could work around it by using a null_resource that only exists when origin shield is disabled. When it runs, it calls the AWS API directly and forces OriginShield.Enabled = false.
resource "null_resource" "cloudfront_origin_shield_disable" {
count = var.create_cloudfront == "yes" && !var.enable_cloudfront_origin_shield ? 1 : 0
triggers = {
enable_origin_shield = var.enable_cloudfront_origin_shield
distribution_id = aws_cloudfront_distribution.default[0].id
script_hash = filemd5("${path.module}/bin/disable-cloudfront-origin-shield.sh")
}
provisioner "local-exec" {
command = "${path.module}/bin/disable-cloudfront-origin-shield.sh ${aws_cloudfront_distribution.default[0].id} wordpress"
}
depends_on = [aws_cloudfront_distribution.default]
}
The null_resource only runs on the transition from enabled to disabled. It fetches the current config, exits early if origin shield is already off, and only patches it when needed.
CLOUDFRONT_CONFIG=$(aws cloudfront get-distribution-config --id "$DISTRIBUTION_ID" --output json)
ETAG=$(echo "$CLOUDFRONT_CONFIG" | jq -r '.ETag')
DISTRIBUTION_CONFIG=$(echo "$CLOUDFRONT_CONFIG" | jq '.DistributionConfig')
jq --arg origin_id "$ORIGIN_ID" '
.Origins.Items = [
.Origins.Items[] |
if .Id == $origin_id then
.OriginShield.Enabled = false
else
.
end
]
' <<< "$DISTRIBUTION_CONFIG" | aws cloudfront update-distribution \
--id "$DISTRIBUTION_ID" \
--distribution-config /dev/stdin \
--if-match "$ETAG"
I distinctly remember being very satisfied that it’s working after spending couple of hours on this bug. Every re-run took minutes! When it finally worked, I felt so relieved.
The bug is still open, but at least our plans are finally clean.